고강도 Nb기 초내열 합금 설계를 위한 기계학습 기반 데이터 분석
Machine Learning-based Data Analysis for Designing High-strength Nb-based Superalloys
Article information
Abstract
Machine learning-based data analysis approaches have been employed to overcome the limitations in accurately analyzing data and to predict the results of the design of Nb-based superalloys. In this study, a database containing the composition of the alloying elements and their room-temperature tensile strengths was prepared based on a previous study. After computing the correlation between the tensile strength at room temperature and the composition, a material science analysis was conducted on the elements with high correlation coefficients. These alloying elements were found to have a significant effect on the variation in the tensile strength of Nb-based alloys at room temperature. Through this process, a model was derived to predict the properties using four machine learning algorithms. The Bayesian ridge regression algorithm proved to be the optimal model when Y, Sc, W, Cr, Mo, Sn, and Ti were used as input features. This study demonstrates the successful application of machine learning techniques to effectively analyze data and predict outcomes, thereby providing valuable insights into the design of Nb-based superalloys.
1. Introduction
오늘날, 기술의 진보와 더불어 환경적으로 건전하고 지 속 가능한 발전에 대한 관심이 커지면서, 현존하는 내연기 관 중에서 가장 우수한 열효율을 지닌 가스 터빈(gas turbine)이 주목 받고 있으며, 또한 가스 터빈의 핵심 부품 소재 중 하나인 초내열 합금이 큰 관심을 받고 있다. 초내 열 합금은 그 정의에 대해 명확히 규정된 바 없으나, 통상 적으로 약 700°C 이상의 고온 환경에서도 우수한 기계적 강도와 내산화 특성, 크리프 특성 등을 가지는 합금을 지 칭한다. 이러한 초내열 합금은 우주, 항공, 원자력 발전과 같은 극한환경에도 필수적으로 요구되며[1], 현재까지 Fe, Co, Ni기 초내열 합금이 상용화된 바 있다. 이 중 Ni기 초 내열 합금은 우수한 고온 특성으로 항공 및 발전 분야에 서 널리 활용되어 왔지만, 융점이 최대 약 1,500°C에 불과 하므로 최대 작동 온도(maximum operating temperature)가 약 1,100°C 수준이며, 그 이상의 초고온 환경에서의 사용 에는 많은 제약이 따른다[2, 3]. 따라서 이러한 소재의 본 질적인 한계를 극복할 수 있는 소재로써 Nb과 Mo같은 고 융점 금속이 주목받고 있다. 이러한 고융점 금속 기반의 합금은 융점이 매우 높고(>2,400°C), 밀도가 비교적 낮으 며(<10 g/mm3), 고온에서의 기계적 성질이 뛰어나 가스 터 빈, 제트 엔진 등의 재료로 각광받고 있다. 특히, Si, Ti, Cr, Al, Hf 등 여러 금속 원소들이 포함된 Nb-Si기 Refractory Metal-Intermetallic Composites(RMIC)는 약 1,350 °C 이상의 고온에서 가지는 뛰어난 물성으로 인해 차세대 고온 재료로 큰 기대를 받고 있다[4, 5].
초내열 합금의 적용에 필수적으로 고려되어야 하는 물 성에는 상온 파괴인성, 고온 강도, 산화 저항성, 크리프 특 성 등이 있다. 위와 같은 물성들에 대하여 산업적으로 적 용 가능한 초내열 합금을 개발하기 위해서 Nb-Si기 RMIC 에 Mo, W, Ta, Zr, Y, B과 같은 원소들을 조성에 포함시 키거나[6-19], 산화물 및 탄화물을 분산시키는 방법들이 연구되었다[20-24]. 또한, unidirectional, directional solidification[ 25, 26], 열처리 공정[27], 분말야금[28] 등 다양한 제조 공정 방법 역시 개발되었다. 하지만, 다원계 합금의 특성상 조성, 공정 변수, 분산물 등의 여러 인자가 합금의 물성에 미치는 영향을 분명하게 분석 및 예측하기 어렵다 는 한계가 존재한다. 특히, 첨가 원소가 많아지고 공정 변 수가 다양해질수록 데이터가 방대해져 변수 간의 인과관 계를 정확하게 파악하기 어려워진다. 또한, 이와 같은 변 수들은 상기한 물성들에 trade-off 되는 영향을 줄 수 있기 에 최적의 물성을 가지는 합금을 설계하는 데에 있어서 난점이 될 수 있다.
이에 대한 해결방안으로 기계학습(machine learning)을 이용한 데이터 통계적 접근방법이 제시될 수 있다. 기계학 습은 컴퓨터가 여러 알고리즘을 통해 학습을 진행하여 데 이터를 분석하고 결과를 예측하는 방법이다. 기계학습을 사용하면 직접적인 분석이 불가능한 물리적으로 많은 양 의 데이터를 빠르고 정확하게 정량적으로 분석하고, 최적 의 알고리즘을 통해 필요한 데이터를 도출할 수 있다. 최 근, 재료과학 분야에서 실험적으로 얻기 힘든 결과를 예측 하기 위해 기계학습을 사용하는 방법이 주목받고 있다 [29-31].
따라서 본 연구에서는 물성에 영향을 미치는 변수가 복 잡해짐에 따라 생기는 다원계 초내열 합금 설계의 한계를 극복하기 위해 기계학습을 적용하였다. 기존 연구 결과를 바탕으로 Nb기 초내열 합금에 대한 상온 인장강도 데이터 베이스를 통해 합금의 물성을 예측하는 최적의 기계학습 모델을 만들고 그 신뢰성을 평가하였다.
2. Experimental
2.1 데이터베이스 구축
Nb기 초내열 합금의 조성 원소의 첨가량이 상온 인장강 도에 미치는 영향을 분석하기 위해서 기존의 논문, 특허 등을 바탕으로 데이터베이스를 구축하였다. 17개 원소 (Nb, Si, T i, Cr, A l, H f, M o, W, Zr, Y, B, C, F e, Ge, Sc, Sn, Re)의 조성을 input feature로, 그에 해당하는 합금의 상온 인장강도를 output feature로 지정했다. 원소 조성의 단위는 원자 퍼센트(atomic percent)로 나타냈으며, 합금에 서 각 원소가 차지하는 분율의 범위는 다음과 같다. Nb:42~90, Si:5~20, Ti:0~25, Cr:0~14, Al:0~4, Hf:0~8.2, Mo:0~10, W:0~10, Zr:0~5, Y:0~0.6, B:0~0.2, C:0~2, Fe: 0~3, Ge:0~5, Sc:0~0.5, Sn:0~1.2, Re:0~0.4. 상온 인장강도 의 단위는 MPa로 나타내었으며, 163~1,386의 값을 가진다.
2.2 상관분석
Nb를 제외한 조성 원소의 분율과 상온 인장강도 사이의 상관분석을 진행하였다. 상관분석이란 두 변수 사이의 양 적 관계를 측정하는 방법이다. 상관분석의 결과는 maximal information coefficient(MIC)[32]와 Pearson’s coefficient of correlation(PCC)[33]를 통해 나타냈다.
MIC는 모집단의 모수를 상정하지 않거나 모집단의 분 포에 의하지 않고 통계적 추측을 진행하는 비모수적 분석 방법이다. 선형 함수, 지수 함수, 주기 함수 등 함수의 종 류에 제한 없이 광범위한 연관성을 식별할 수 있기 때문 에 고차원 빅데이터의 비선형 상관관계를 파악하는데 효 과적이다. 0에서 1 사이의 값을 가지며 0에 가까울수록 input과 output 간의 상관관계가 적음을, 1에 가까울수록 input과 output 간의 상관관계가 큼을 나타낸다.
PCC는 두 인자 간의 선형적인 상관관계를 나타낸다. -1 에서 +1 사이의 값을 가지며 PCC 값이 양수일 때는 한 변수가 증가하면 다른 변수 역시 증가하고, 한 변수가 감 소하면 다른 변수 역시 감소한다. PCC 값이 음수일 때는 한 변수가 증가하면 다른 변수는 감소하고, 한 변수가 감 소하면 다른 변수는 증가하는 양상을 보인다. 또한 PCC의 절댓값인 |PCC|는 상관관계의 크기를 나타내며, 1에 가까 울수록 선형적인 관계가 큰 것을, 0에 가까울수록 선형 상 관관계가 없음을 나타낸다. 그렇기 때문에 비선형적인 관 계를 파악할 수는 없다.
2.3 기계학습
Base가 되는 Nb을 제외한 16개의 원소를 input feature 로 하여 output feature인 상온 인장강도를 예측하는 기계 학습을 진행하였다. 기계 학습에는 random forest(RF)[34], nearest neighbor(NN)[35], Bayesian ridge regression(BR) [36], support vector machine(SVM)[37]의 네 가지 알고리 즘이 사용되었다.
RF 알고리즘은 여러 개의 개별 분류기로 구성된 의사 결정 나무를 생성하고, 이를 결합하고 투표를 진행해 성능 이 가장 뛰어난 모델을 만드는 알고리즘이다. 모델들을 무 작위로 생성하고, 넓은 범위의 계산을 수행하기 때문에 모 델이 주어진 데이터에만 적응해 다른 데이터에는 반응하 지 못하는 과적합 현상을 방지하여 높은 신뢰성을 가진다 [38]. NN 알고리즘은 임의의 데이터 주변에 있는 데이터 와의 관계를 토대로 결과를 예측하는 알고리즘이다. ‘주 변’이 되는 데이터의 수를 적게 하면 보다 세밀한 규칙성 을 따라 모델을 구성하고, 크게 하면 데이터가 가진 넓은 범위의 경향성을 따르게 된다[39]. BR 알고리즘은 기본적 으로 데이터의 산포도와 가장 적합한 선형 함수를 계산해 결과를 예측하는 방식이며, 과적합을 방지하기 위해 여러 제약식을 통해 함수를 조정한다[36]. SVM 알고리즘은 어 떠한 선형 함수와 가까운 범위 안에 최대한 많은 데이터 가 포함되도록 회귀식을 계산하고, 그 회귀식을 통해 결과 값을 예측하는 알고리즘이다[40].
상관분석을 통해 구한 MIC, |PCC|별 상관계수의 순위를 바탕으로 가장 높은 상관계수를 가지는 input feature의 개 수에 따른 기계학습의 신뢰도를 결정계수(coefficient of determination) R2로 나타내었다. R2는 종속변수가 독립변 수에 의해 설명되는 정도를 나타내며, 0~1의 값을 가지고, 1에 가까울수록 신뢰도가 높음을 의미한다.
상관분석과 기계학습의 모든 과정은 파이썬 기반의 오 픈 소스 데이터 툴킷인 Advanced data SciEnce toolkit for Non-Data Scientists(ASCENDS)[41, 42]를 통해 진행되었 다. 마지막으로, 상관분석과 기계학습의 결과를 기존 연구 사례를 바탕으로 재료 과학적인 측면에서 분석하였다.
3. Results and Discussion
3.1 상관분석
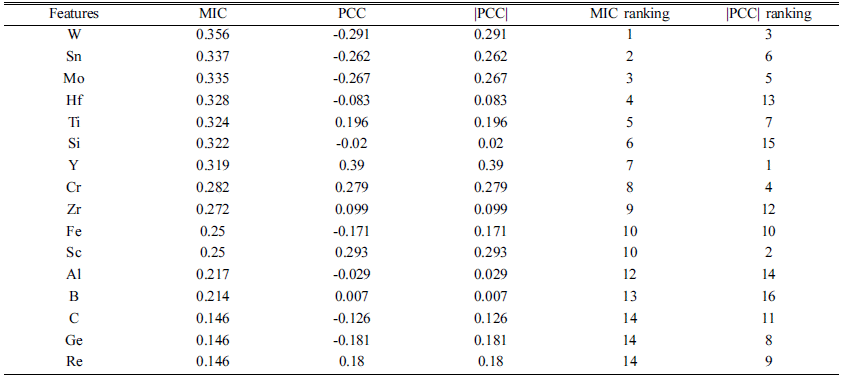
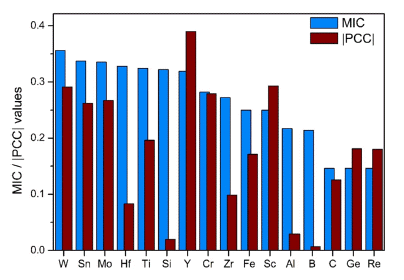
Figure 1과 Figure 2, Table 1에서는 합금의 원소 조성과 상온 인장강도 사이의 상관분석을 진행한 결과를 각각 MIC와 |PCC|, PCC로 나타내었다. MIC는 0.146~0.321의 값을 가지고, 평균값은 0.265이다. |PCC|는 0.07~0.39의 값 을 가지며, 평균값은 0.180이다. 이와 같이 상관계수가 작 은 값을 보이는 것은 합금을 구성하는 개별적인 원소와 상온 인장강도 사이의 선형적 또는 비선형적인 관계의 정 도가 적음을 의미한다. 각각의 원소가 물성에 영향을 미치 기 보다는 여러 원소가 복합적으로 구성하는 상이나 기타 변수에 의해 인장강도가 변화하기 때문이다.
Results of correlation analysis between alloying elements (W, Sn, Mo, Hf, Ti, Si, Y, Cr, Zr, Fe, Sc, Al, B, C, Ge, Re) and room-temperature tensile strength using MIC and |PCC| algorithms.
Results of correlation analysis between alloying elements and room-temperature tensile strength using PCC algorithm.

Ranked scores of input features from correlation analysis with MIC, PCC and |PCC|
또한, 어떠한 원소의 첨가가 합금의 기계적 성질의 분명 한 영향을 미친다고 해도, 상관분석의 결과에서는 원소의 조성과 인장강도 사이에 비례적인 관계가 성립하지 않을 수 있다. 인장강도의 향상 메커니즘에서는 합금의 기지가 되는 Nb 고용체 상과 강화 효과를 보여주는 다른 상이 적 절한 비율로 구성되는 것이 중요하기 때문이다. 또한, 상 관분석에 사용된 데이터의 한계로 인해 원소의 영향이 반 영되지 않는 경우도 존재한다. 이러한 이유로 인해 조성과 물성 간의 상관관계는 정형적인 분포도로 나타나지 않는 경우가 많고, 이는 M IC와 |PCC|값이 작아지는 결과로 이 어진다.
상관계수가 높게 계산된 원소들인 W, Sn, Hf, Cr, Sc이 합금의 물성에 미치는 영향을 재료 과학적인 측면에서 분 석하였다. Nb기 초내열 합금에 W가 첨가되었을 때, 원분 말 안에서 편석된 W 분말이 Nb 기지와의 합금화를 방해 하고, 융용되지 않은 W 구역을 생성하여 상온 인장강도를 감소시킨다[43]. 이로 인해 W의 PCC 값이 음수로 도출되 었음을 알 수 있다. Sn의 첨가는 Nb-Si 합금에서 (Nb, Ti)3(Sn, Ti)를 형성하고, γ-M5Si3의 형성을 억제한다. 또한, Nb-Si-Ti 합금에서 (Nb, Ti)3Si의 형성을 억제하고, Nb-Si 합금에서 강도의 향상은 주로 Nb5Si3 상과 Nb3Si 상에 의 하여 이루어지기 때문에 인장강도의 저하로 이어진다[44, 45]. Hf와 Cr은 Nb 합금에 첨가되어 치환형 고용체로 작 용할 때, 공정 구조의 부피 분율을 증가시키는 직접 고용 강화에 의해 인장강도를 향상시킨다[46]. 또한, Sc의 첨가 는 Nb5Si3상의 세밀한 미세구조를 유도하고, 이는 합금이 더 큰 응력을 견딜 수 있게 만들며, 하중의 방향과 평행한 계면을 더 생성해 interfacial sliding을 방해하고 결과적으 로 합금의 인장강도를 증가시킨다[47]. 이런 원소들은 Nb 합금에서 인장강도에 미치는 영향이 뚜렷하게 나타나므로 높은 M IC와 |PCC|값을 가지는 것으로 해석될 수 있다.
3.2 기계학습
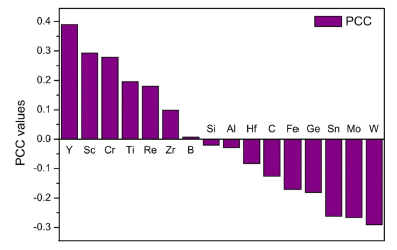
Figure 3과 4는 각각 M IC, |PCC| 크기의 순서대로 기계 학습에 사용한 input feature의 수에 따른 알고리즘별 R2를 보여준다. |PCC| 기준 input feature의 개수가 5개일 때를 제외하면, 모든 모델에서 input feature가 1일 때 R2는 가 장 작은 값을 보였다. 이는 적은 수의 인자로는 인장강도 의 변화를 정확하게 예측하기 어렵기 때문에 나타난 결과 이다. 전술한 바와 같이 합금의 물성에는 여러 원소가 이 루는 상의 형성과 공정 변수 등 많은 요인이 작용한다. 또 한, 대체적으로 input feature의 수가 증가할수록 R2 역시 증가하는 경향을 보이지만, 선형적으로 뚜렷한 비례관계 는 확인할 수 없었다. 기계학습의 기준이 되는 상관분석의 결과는 하나의 원소와 인장강도 간의 관계를 측정한 것인 반면, 알고리즘을 통해 평가한 학습은 여러 인자의 변화에 의한 목표 물성의 값을 예측한 것이기 때문에 상관분석과 기계학습 간의 차이가 발생한 것으로 예상된다.
Coefficient of determination (R2) of machine learning model using four algorithms; random forest (RF), nearest neighbor (NN), Bayesian ridge regression (BR), support vector machine (SVM). Results of correlation analysis with MIC was employed as a function of number of top ranking features.
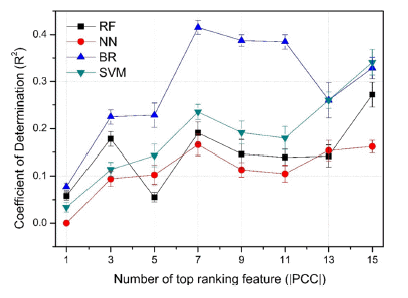
Coefficient of determination (R2) of machine learning model using four algorithms; random forest (RF), nearest neighbor (NN), Bayesian ridge regression (BR), support vector machine (SVM). Results of correlation analysis with |PCC| was employed as a function of number of top ranking features.
모든 기계학습 모델 중 |PCC|기준 상위 7개의 원소를 input feature로 하였을 때의 BR 모델이 가장 높은 R2값을 보였다. 이때 인자로 포함된 원소는 Y, Sc, W, Cr, Mo, Sn, Ti이며, R2값은 0.415였다. 이 R2값은 기계 학습의 정확도 를 나타내는 수치가 아닌, 종속변수가 독립변수에 의해 설 명되는 정도이다. 즉, BR 알고리즘을 통해 합금의 상온 인 장강도를 예측할 때 인장강도에 미치는 요인의 약 41.5% 는 위의 7개 원소의 변화를 통해 예측할 수 있음을 의미 한다.
Figure 5는 numbers of top ranking에 따른 알고리즘별 R2의 평균값을 보여준다. MIC를 기준으로 하였을 때는 RF > SVM>BR > NN 순서로, |PCC|를 기준으로 하였을 때는 BR > SVM> RF > NN 순서로 나타났다. 모든 알고 리즘 중 |PCC|를 기준으로 계산한 BR 알고리즘의 R2값이 가장 크게 측정되었다. 나머지 RF, NN, SVM 알고리즘의 R2값은 M IC 기준으로 진행하였을 때 더 큰 값을 보였다. MIC는 함수의 종류에 제한 없이 광범위한 연관성을 식별 하는 상관분석 방법이고, RF 알고리즘은 이런 종류의 데 이터를 여러 예측의 조합을 통해 분석하여 과적합에 방지 하기 때문에 M IC를 기준으로 모델을 예측했을 때, RF 알 고리즘의 R2값이 가장 크게 나타난 것으로 예상된다. 또 한, |PCC|는 선형적인 상관관계를 나타내는 방법이고, BR 알고리즘도 선형 회귀를 통해 결과를 예측하는 방식을 사 용하기 때문에 그 경향성이 반영된 것으로 예측된다.
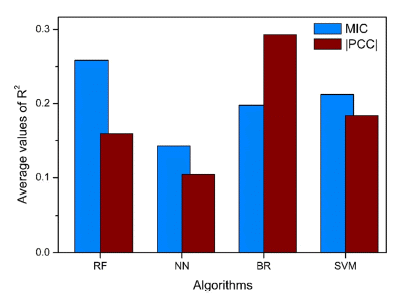
Average values of R2 obtained from machine learning model with separate algorithms and correlation analysis.
4. Conclusion
뛰어난 기계적 성질을 가지는 Nb기 초내열 합금의 조성 설계를 위해 기계학습을 이용한 데이터 통계적 접근 방법 을 사용했다. 상관분석을 통해 16개의 원소가 합금의 상 온 인장강도에 미치는 영향을 재료과학적인 측면에서 분 석하고, 기계학습을 이용하여 합금의 상온 인장강도를 예 측하는 최적의 모델을 도출하였다. 결과는 다음과 같다.
상관분석을 통해 개별 원소의 조성과 상온 인장강도 사이의 상관계수를 M IC, PCC, |PCC|로 나타내고 그 순위를 매겼다. MIC와 |PCC|가 큰 값을 가진 원소들 인 W, Sn, Hf, Cr, Sc이 Nb기 초내열 합금의 상온 인 장강도에 미치는 영향을 분석하였고, 위 원소들은 합 금에 첨가되었을 때 미세구조를 변화시키고 물성의 변화에 큰 영향을 미쳐 상관계수가 높게 나오는 것으 로 예측된다.
MIC와 |PCC|의 순위를 바탕으로 input feature의 개수 에 따른 알고리즘별 결정계수를 구하는 기계학습을 진행하였다. 대체적으로 input feature의 개수가 많을 수록 결정계수가 크게 나타났지만, 증감에서 뚜렷한 비례관계는 없었다. 알고리즘별 R2의 평균은 M IC를 기준으로 하였을 때가 더 큰 값을 보였다. 하지만, 가 장 큰 R2값인 0.415를 가지는 모델은 |PCC|를 기준으 로 한 BR 알고리즘이었다. |PCC|가 가장 높게 측정된 7개의 원소인 Y, Sc, W, Cr, Mo, Sn, Ti을 input feature로 하였을 때의 R2값이 0.415로 최댓값을 보였 다. 본 분석에 의하면 평균적으로 물성을 예측하는 알고리즘의 정확도는 MIC를 기준으로 할 때가 더 높 지만, BR 알고리즘에 한하여 PCC가 높은 원소를 input feature로 계산한 모델이 합금의 원소 조성을 통 해 상온 인장강도를 예측하는 최적의 모델임을 보여 준다.
Acknowledgement
본 연구는 정부(과학기술정보통신부)의 재원으로 한국 연구재단의 지원을 받아 수행된 연구임(NRF-2022M3H 4A1A04085307, NRF-2022R1A4A5033917).